Nowadays, probably the two most used programming languages for machine learning are python and R. Both have advantages and disadvantages. With tools like rpy2 or Jupyter with the IRKernel, it is possible to integrate R and python into a single application and make them “talk” with each other. However, it is important to know how they work individually before the connection of these two programming languages. I will try to show some of the similarities and differences between the commands, functions and environment. For example, both languages could have very similar commands but these commands could lead to different results.
There are hundreds books about python and R with different flavours. Basic, advanced, applied, how to, free, paid, master, ninja, etc. Because I used a lot of programming applied to real world scenario I randomly biased decided to, use as a initial guide, a free book called A Hands-On Introduction to Using Python in the Atmospheric and Oceanic Sciences by prof. Johnny Lin (the main idea is to reproduce a machine learning portable code so i will change the reference later). Thus I will follow some examples of this book and give the insights about the python/R relation.
Nevertheless, It is imperative to know what version of the programming language one is using. Commands, types, syntax, can change over versions. Here I am using python 2.7.13 and R 3.2.2, both 64-bit on a Ubuntu 16.04.
Basic operators
In R, the elementary arithmetic operators are the usual +, -, *, / and ^ for raising to a power. The only difference to python is the exponentiation operator which is **.
Basic variables
Python and R are dynamically typed, meaning that variables take on the type of whatever they are set to when they are assigned. Additionally, the variable’s type can be changed (at run time) without changing the variable name. Lets start with two of the most important basic types: integer and float (called double in R). Here it is possible to see the first few differences between the languages. The integer type from the R documentation:
Integer vectors exist so that data can be passed to C or Fortran code which expects them, and so that (small) integer data can be represented exactly and compactly. Note that current implementations of R use 32-bit integers for integer vectors, so the range of representable integers is restricted to about +/-2*10^9: doubles can hold much larger integers exactly.
There are two integers types in python: plain and long.
Plain integers (also just called integers) are implemented using long in C, which gives them at least 32 bits of precision (sys.maxint is always set to the maximum plain integer value for the current platform, the minimum value is -sys.maxint – 1). Long integers have unlimited precision.
How about the float (or double) types? From both programming languages ultimately how double (or float) precision numbers are handled is down to the CPU/FPU and compiler (i.e. for the machine on which your program is running).
OK lets try a simple example. This example is the same as Example 4 on chapter 3 of our guide book. Lets say we have the following variables:
a = 3.5
b = -2.1
c = 3
d = 4
If we run the operators described above in python we have:
print(a*b) #case 1
print(a*d) #case 2
print(b+c) #case 3
print(a/c) #case 4
print(c/d) #case 5
## -7.35
## 14.0
## 0.9
## 1.16666666667
## 0
Repeating the same steps for R we obtain:
## [1] -7.35
## [1] 14
## [1] 0.9
## [1] 1.166667
## [1] 0.75
On cases 2, 4 and 5 we had different results. On case 4, the difference should be related to the float/double representation. Thus it is expected a difference on precision. However it does not mean that R has less precision than python in this example. It could be only the way R shows the variable to the user. Yes, unfortunately R can mislead you. For example, on case 2 the numbers are technically the but they are shown in a different way. The fact that R shows 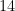 instead of
instead of  does not mean that the value is integer and not double. Let’s use the functions
does not mean that the value is integer and not double. Let’s use the functions is.integer() and is.double() to check the type of the variable of the result on case 2.
is.integer(a*d)
is.double(a*d)
## [1] FALSE
## [1] TRUE
Remember when the “dynamically typed”? The programming language automatically decides what type a variable is based on the value operation. Again from the python documentation:
Python fully supports mixed arithmetic: when a binary arithmetic operator has operands of different numeric types, the operand with the “narrower” type is widened to that of the other, where plain integer is narrower than long integer is narrower than floating point is narrower than complex. Comparisons between numbers of mixed type use the same rule.
That explains why in case 2 we have a float. You can check using the function isinstance().
print(isinstance( a*c, ( int, long ) ))
print(isinstance( a*c, ( float ) ))
## False
## True
How about case 5? Case 5 is a little bit more interesting. For python we are dealing with 2 integers, thus the result should be integer. That is why we have  because python does integer division and returns only the quotient.
because python does integer division and returns only the quotient.
print(isinstance( c/d, ( int, long ) ))
print(isinstance( c/d, ( float ) ))
## True
## False
How about R? Here is the reason (from the documentation):
For most purposes the user will not be concerned if the “numbers” in a numeric vector are integers, reals or even complex. Internally calculations are done as double precision real numbers, or double precision complex numbers if the input data are complex.
Thus, it is important to keep this in mind because you can have different results.
Similarities not so similar
As a final remark I’d like to mention about the similarities not so similar of the operator ^ in and python. Yes, python also has the same operator but it is the bitwise XOR operator, which is different of exponentiation. Click here for more information about bitwise operators in python.
If you have any question, suggestion or opinion about this post please feel free to write a comment below.

