
Last post I talked a little bit about the two most used programming languages for machine learning (python and R) and how they handle operators and types. In this post i will extend the talk about types in python and R. In particular logical operators and Boolean. Here I am using python 2.7.13 and R 3.3.3, both 64-bit on a Ubuntu 16.04 and I am using the free book called A Hands-On Introduction to Using Python in the Atmospheric and Oceanic Sciences by prof. Johnny Lin as a guide.
Logical operators
The logical operators are <, <=, >, >=, == for exact equality and != for inequality (valid for both languages). However there are some differences between python and R when comparing logical expressions. In R if test1 and test2 are logical expressions, then test1 & test2 is their intersection (“and”), test1 | test2 is their union (“or”), and !test1 is the negation of test1. Thus:
a = TRUE
b = FALSE
a & b
a | b
!a
## [1] FALSE ## [1] TRUE ## [1] FALSE
In python test1 and test2 is their intersection (“and”), test1 or test2 is their union (“or”), and not test1 is the negation of test1.
a = True
b = False
print(a and b)
print(a or b)
print(not a)
## False ## True ## False
Boolean variables
Python and R are case sensitive, so capitalization matters!!!! Therefore, TRUE != True. R also allows the use of T and F but it is not recommended. From the R documentation:
The elements of a logical vector can have the values
TRUE,FALSE, andNA(for “not available”). The first two are often abbreviated asTandF, respectively. Note however thatTandFare just variables which are set toTRUEandFALSEby default, but are not reserved words and hence can be overwritten by the user. Hence, you should always use TRUE and FALSE.
Thus doing a simple example in R:
c = T
a == c
## [1] FALSE
And this is why it is NOT recommended:
T = 10
a == T
## [1] FALSE
In some languages, the integer value zero is considered FALSE (or False) and the integer value one is considered TRUE (or True). From the R documentation:
Logical vectors may be used in ordinary arithmetic, in which case they are coerced into numeric vectors, FALSE becoming 0 and TRUE becoming 1.
Doing a simple example in R:
a == TRUE
b == FALSE
10 + a
10 + b
## [1] TRUE ## [1] TRUE ## [1] 11 ## [1] 10
The Python’s version I am using here (2.7.13) follows the same convention:
print(1 == a)
print(0 == b)
print(10 + a)
print(10 + b)
## True ## True ## 11 ## 10
How about the operators? Lets use the same rule with R:
a & 1
a & 0
1 & a
2 & a
0 & a
## [1] TRUE ## [1] FALSE ## [1] TRUE ## [1] TRUE ## [1] FALSE
And using python:
print(a and 1)
print(a and 0)
print(1 and a)
print(2 and a)
print(0 and a)
## 1 ## 0 ## True ## True ## 0
Remember Python and R are dynamically typed but they sometimes handle variables in a different way? You can click here and see how python handles the truth value testing.
Similarities not so similar
As a final remark I’d like to mention about the similarities not so similar of the operators & and | in R and python. Yes, python also has the same operators but they are the bitwise logical operators, which is slight different of what we are doing here. For example:
print(a & 1)
print(a & 0)
print(1 & a)
print(2 & a)
print(0 & a)
## 1 ## 0 ## 1 ## 0 ## 0
In R the bitwise operators are bitwAnd() and bitwOr(), but this is another post. Click here for more information about bitwise operators in python and R.
If you have any question, suggestion or opinion about this post please feel free to write a comment below.
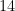 instead of
instead of  does not mean that the value is integer and not double. Let’s use the functions
does not mean that the value is integer and not double. Let’s use the functions  because python does integer division and returns only the quotient.
because python does integer division and returns only the quotient.



