
In this post I will talk a little bit about how python and R work with vectors. I am using python 2.7.13 and R 3.4.3, both 64-bit on a Ubuntu 16.04 and I am also using the free book called A Hands-On Introduction to Using Python in the Atmospheric and Oceanic Sciences by prof. Johnny Lin as a guide.
Creating vectors
The first thing about a vector is how to create one. There are several ways to create a vector in R. For example, if one needs to create a logical vector:
a = vector(mode = "logical", length = 5)
b = c(FALSE, FALSE, FALSE, FALSE, FALSE)
c = rep(FALSE,5)
## [1] FALSE FALSE FALSE FALSE FALSE ## [1] FALSE FALSE FALSE FALSE FALSE ## [1] FALSE FALSE FALSE FALSE FALSE
or a numerical vector:
a = vector(mode = "numeric", length = 5)
b = c(0, 0, 0, 0, 0)
c = rep(x=0, 5)
## [1] 0 0 0 0 0 ## [1] 0 0 0 0 0 ## [1] 0 0 0 0 0
The vector() function produces a vector of the given length and mode, the c() function is a generic function which combines its arguments and rep() function replicates the values in x also returning a vector.
In python we can use the numpy package which has lots of methods to create and manipulate arrays/vectors. Thus importing the package numpy and generating the same vectors in python:
import numpy as np
a = np.array([False,False,False,False])
b = np.full(4, False, bool)
print a
print b
## [False False False False] ## [False False False False]
or a numerical vector:
import numpy as np
a = np.array([0,0,0,0])
b = np.full(4, 0, float)
print a
print b
## [0 0 0 0] ## [ 0. 0. 0. 0.]
Why are they different? Remember the dynamical typing? Vector a is a vector of integers and b is a vector of float. The attribute dtype gives the data-type of the array’s elements:
c = np.array([0.0,0.0,0.0,0.0])
print a.dtype
print b.dtype
print c
print c.dtype
## int64 ## float64 ## [ 0. 0. 0. 0.] ## float64
Indexing Vectors
One major difference between python and R is how they address the element in the vector. In python the element addresses start with zero, so the first element of vector a is a[0], the second is a[1], etc.
import numpy as np
d = np.array(range(1,5))
print d
print d[0], d[3]
## [1 2 3 4] ## 1 4
In R the element addresses follows the ordinal value thus starting from one. Consequently the first element of vector a is a[1], the second is a[2], etc.
d = seq(4)
print(d)
cat(d[1], d[4], sep=" ")
## [1] 1 2 3 4 ## 1 4
Be careful!!!!
Python and R have the same method range() but they do different things. In python range() returns a list containing an arithmetic progression of integers. range(i, j) returns ![([i, i+1, i+2,\ldots , j-1])](https://s0.wp.com/latex.php?latex=%28%5Bi%2C+i%2B1%2C+i%2B2%2C%5Cldots+%2C+j-1%5D%29+&bg=ffffff&fg=000000&s=0&c=20201002)
i=0.
f = range(5)
g = range(2,5)
print f
print g
## [0, 1, 2, 3, 4] ## [2, 3, 4]
In R the methods similar to range() are seq(), seq_along(), seq_len() (please check the R documentation to see the differences between them) which generates regular sequences. However the default starting value is 1.
f = seq(5)
g = seq(2,5)
print(f)
print(g)
## [1] 1 2 3 4 5 ## [1] 2 3 4 5
The method range() in R returns a vector containing the minimum and maximum of all the given arguments.
range(f)
range(5)
## [1] 1 5 ## [1] 5 5
If you have any question, suggestion or opinion about this post please feel free to write a comment below.
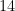 instead of
instead of  does not mean that the value is integer and not double. Let’s use the functions
does not mean that the value is integer and not double. Let’s use the functions  because python does integer division and returns only the quotient.
because python does integer division and returns only the quotient.